Puppeteer Screenshot Leitfaden: Full Page, PDF, Headless
# Puppeteer Screenshot Leitfaden: Full Page, PDFs & Headless Chrome (2026)
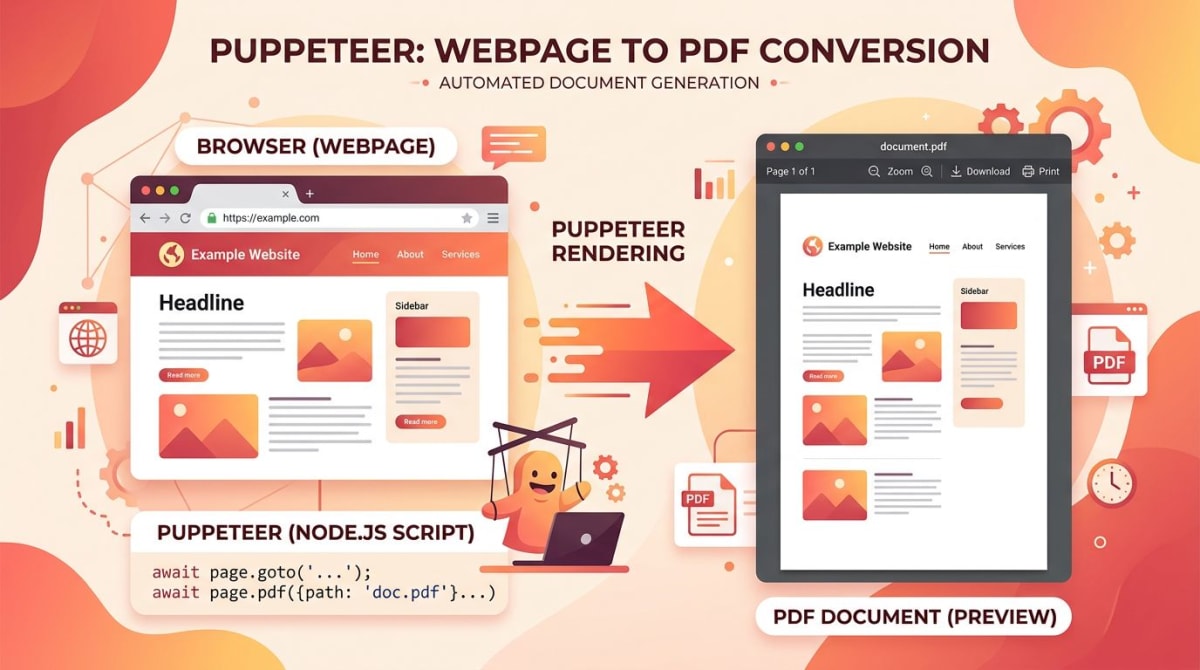
Puppeteer ist eine Node.js-Bibliothek, die Chrome über das DevTools Protocol steuert. Du rufst page.screenshot() auf, um einen Viewport, eine ganze Seite, ein Element oder eine zugeschnittene Region zu erfassen. Du rufst page.pdf() auf, um dieselbe Seite als PDF zu rendern. Es ist die richtige Wahl, wenn du First-Party-Chrome-Verhalten, eine kleine API und eine enge Bindung an den Browser willst.
Wann Puppeteer das richtige Tool ist
Puppeteer kommt vom Chrome-Team. Es folgt Chrome eng und gibt Chrome-spezifische Features wie PDF-Rendering frei. Nutze es, wenn du folgendes willst:
- Server-seitige Screenshots dynamischer Seiten (Dashboards, Diagramme, Social Previews).
- Web Scraping, das JavaScript-Ausführung und Chrome-Eigenheiten braucht.
- HTML-zu-PDF-Rendering mit Headern, Footern und CSS-Druckstilen.
- End-to-End-Tests, bei denen du nur Chrome brauchst und eine Abhängigkeit weniger willst.
Wenn du Cross-Browser-Abdeckung (Firefox, WebKit) oder einen reichhaltigeren Test-Runner brauchst, siehe unseren Puppeteer vs Playwright Vergleich. Für die entsprechenden Rezepte in Playwright springe zum Playwright Screenshot Leitfaden.
Setup: Installation und Smoke-Test
Du hast zwei Installationsoptionen:
# Option 1: bündelt einen geprüften Chromium-Build
npm install puppeteer
# Option 2: bring deine eigene Chrome-Binary mit (kleinere Installation)
npm install puppeteer-coreNutze puppeteer für lokale Entwicklung und die meisten Server. Nutze puppeteer-core, wenn du bereits eine Chrome-Installation verwaltest (Docker-Images, Lambda-Layer, CI-Runner mit vorinstalliertem Chromium).
Smoke-Test mit einem Einzeiler:
import puppeteer from 'puppeteer';
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({ path: 'smoke.png' });
await browser.close();Wenn smoke.png in deinem Arbeitsverzeichnis landet, bist du startklar. Lies die volle API auf der Puppeteer-Doku-Seite und im GitHub-Repo.
Kern-Screenshot-Operationen
Diese acht Rezepte decken 90 % der echten Puppeteer-Screenshot-Arbeit ab.
Standard-Seiten-Screenshot
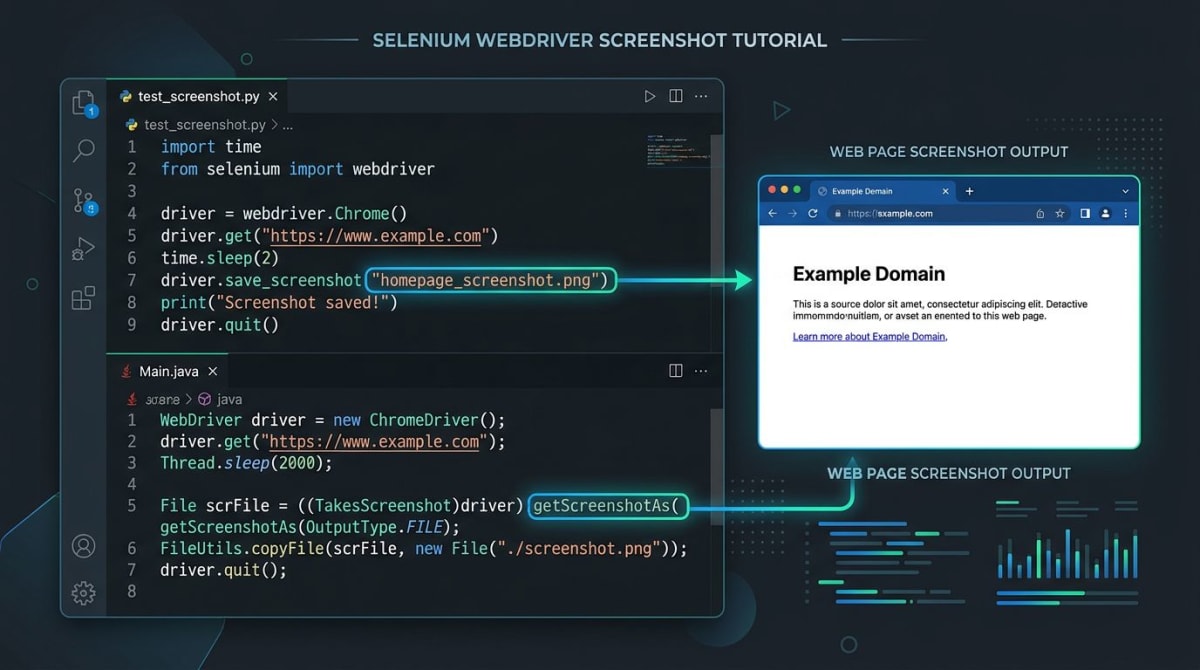
Standardmäßig erfasst page.screenshot() nur den sichtbaren Viewport (1280x720, falls du keinen Viewport setzt).
await page.screenshot({ path: 'page.png' });Die path-Option schreibt die Datei auf die Festplatte. Lass sie weg, um stattdessen einen Buffer zu bekommen.
Full-Page-Screenshot
Übergib fullPage: true, um die gesamte scrollbare Höhe zu erfassen, nicht nur den Viewport.
await page.screenshot({ path: 'full.png', fullPage: true });Puppeteer vergrößert den Viewport im Hintergrund, malt das volle Dokument und stellt dann die alte Größe wieder her. Das ist die häufigste Ursache für leeren Raum bei lazy-geladenen Seiten — siehe den Stolperfallen-Abschnitt unten.
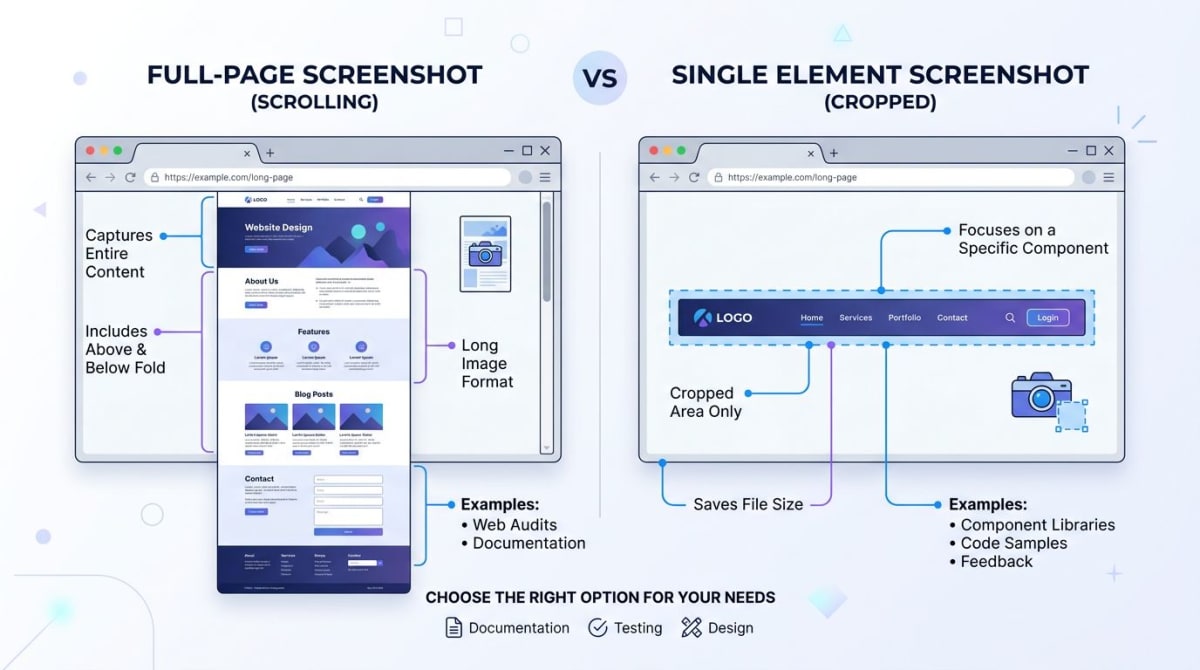
Element-Screenshot
Hole dir einen Handle mit page.$() (oder page.waitForSelector()) und rufe dann screenshot() darauf auf.
const el = await page.$('h1');
await el.screenshot({ path: 'h1.png' });Element-Screenshots scrollen das Element in den Sichtbereich und schneiden auf seine Bounding Box zu. Perfekt für OG-Cards, Diagramm-Exporte und Komponenten-Snapshots.
Eine Region zuschneiden
Überspringe den Element-Handle und übergib rohe Koordinaten mit clip.
await page.screenshot({
path: 'region.png',
clip: { x: 0, y: 0, width: 600, height: 400 },
});Nutze Clipping, wenn du genaue Pixel-Offsets kennst. Du kannst zum Beispiel ein fixes Map-Widget oben auf einer Seite erfassen.
Statt einer Datei einen Buffer holen
Lass path weg und der Aufruf gibt einen Buffer zurück. Nützlich zum Streamen zu S3, Posten in Slack oder Pipen in Sharp.
const buffer = await page.screenshot({ encoding: 'binary' });
// buffer ist ein Node.js-Buffer, den du hochladen, transformieren oder streamen kannstCustom Viewport und Retina-Ausgabe
Setze den Viewport vor dem Navigieren, um die Canvas-Größe zu steuern. Erhöhe deviceScaleFactor für scharfe 2x-Retina-Ausgabe.
await page.setViewport({
width: 1920,
height: 1080,
deviceScaleFactor: 2, // 2x = retina, Dateigröße verdoppelt sich
});Ein deviceScaleFactor von 2 mit einem 1920x1080-Viewport gibt dir ein 3840x2160-PNG. Bleib bei 1 für Thumbnails und CI-Artefakte, wo Größe wichtiger ist als Schärfe.
PDF-Generierung
Das ist Puppeteer's Signaturfunktion gegenüber Playwright. PDF-Rendering funktioniert nur im headless-Modus und nur in Chrome.
await page.pdf({
path: 'page.pdf',
format: 'A4',
printBackground: true,
margin: { top: '20mm', right: '15mm', bottom: '20mm', left: '15mm' },
landscape: false,
displayHeaderFooter: true,
headerTemplate: '<div style="font-size:10px; width:100%; text-align:center;">Quarterly Report</div>',
footerTemplate: '<div style="font-size:10px; width:100%; text-align:center;"><span class="pageNumber"></span> / <span class="totalPages"></span></div>',
});Setze printBackground: true, um CSS-Hintergrundfarben und -Bilder zu behalten. Nutze ein @media print-Stylesheet, um Nav, Banner und Chat-Widgets auszublenden. Das gerenderte PDF respektiert dein Druck-CSS.
JPEG, PNG und WebP
PNG ist Standard. Wechsle zu JPEG, wenn du kleinere Dateien willst und keine Transparenz brauchst.
await page.screenshot({ path: 'page.jpg', type: 'jpeg', quality: 80 });
await page.screenshot({ path: 'page.webp', type: 'webp', quality: 80 });Quality läuft von 0 bis 100. Für Dashboards und Diagramme spart JPEG bei 75-85 60-70 % gegenüber PNG ohne sichtbaren Verlust.
Versteckte DOM-Elemente
Versteckte Elemente werden in den Sichtbereich gescrollt, aber nur für Element-Screenshots. Für Full-Page- oder Clip-Erfassungen führe zuerst einen manuellen Scroll aus, um Lazy Loader aufzuwecken.
await page.evaluate(async () => {
await new Promise((resolve) => {
let total = 0;
const distance = 200;
const timer = setInterval(() => {
window.scrollBy(0, distance);
total += distance;
if (total >= document.body.scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});Diese Schleife malt jeden lazy Abschnitt, bevor du erfasst. Jetzt schließt fullPage: true alles unterhalb der Falz ein.
Häufige Muster
Ein paar wiederkehrende Muster zeigen sich in fast jedem Puppeteer-Skript.
Vor der Erfassung auf Inhalte warten
Network Idle und Selector-Waits sind die zwei zuverlässigen Hooks.
await page.goto('https://example.com', { waitUntil: 'networkidle2' });
await page.waitForSelector('main article');
await page.waitForNetworkIdle({ idleTime: 500 });
await page.screenshot({ path: 'ready.png' });waitForNetworkIdle() löst auf, sobald 0 Anfragen für idleTime ms in Bearbeitung sind. Es ist die moderne Lösung für zufällige setTimeout()-Waits.
Authentifizierung über Cookies
Überspringe langsame Login-Flows, indem du Cookies vor dem Navigieren setzt.
await page.setCookie({
name: 'session',
value: process.env.SESSION_TOKEN,
domain: '.example.com',
});
await page.goto('https://example.com/dashboard');
await page.screenshot({ path: 'dashboard.png', fullPage: true });Für OAuth führe ein einmaliges Login-Skript aus, das page.cookies() in einer JSON-Datei speichert. Lade dann diese Datei in deinem Screenshot-Job.
Mobile-Emulation
Puppeteer liefert Geräteprofile, die zu echten iPhone-, Pixel- und iPad-Spezifikationen passen.
import puppeteer, { KnownDevices } from 'puppeteer';
const iPhone = KnownDevices['iPhone 14 Pro'];
await page.emulate(iPhone);
await page.goto('https://example.com');
await page.screenshot({ path: 'iphone.png' });emulate() setzt Viewport, User Agent und deviceScaleFactor in einem Aufruf. Ideal, um Layout-Bugs auf Mobilgeräten zu fangen.
Headless versus headful
Headless ist Standard. Chrome 112 hat den "neuen headless"-Modus hinzugefügt. Er nutzt denselben Code-Pfad wie der reguläre Browser, keine separate Binary. Puppeteer 22 und neuer setzen ihn standardmäßig ein.
// Headless (Standard — schnell, kein sichtbares Fenster)
const browser = await puppeteer.launch();
// Headful (sichtbares Fenster — nützlich zum Debuggen)
const browser = await puppeteer.launch({ headless: false });
// Erzwinge altes headless, wenn eine Site neues headless erkennt
const browser = await puppeteer.launch({ headless: 'shell' });Nutze headful, um Timing-Probleme und CSS-Bugs zu debuggen. Nutze headless überall sonst — es ist schneller und braucht weniger Speicher. Der neue headless-Modus rendert wie ein echter Browser. Anti-Bot-Sites, die die alte headless-Binary geflaggt haben, flaggen deinen Traffic seltener.
Genug von langweiligen Screenshots? Probier ScreenSnap Pro.
Wunderschöne Hintergründe, professionelle Annotationen, GIF-Aufnahme und sofortiges Cloud-Sharing — alles in einer App. Einmalig 29 $, für immer deins.
Sieh, was es kannHäufige Stolperfallen
Diese vier Probleme machen die meisten "Lokal funktioniert es, in CI bricht es"-Tickets aus.

Lazy-geladene Bilder verpassen den Screenshot
Seiten mit loading="lazy" oder IntersectionObserver malen Bilder erst, wenn sie in den Viewport eintreten. Eine blinde fullPage: true-Erfassung zeigt leere Kästen.
Lösung: Scrolle das volle Dokument mit dem Helper aus dem Versteckte-Elemente-Abschnitt und rufe dann waitForNetworkIdle() vor dem Screenshot auf.
Animationen erzeugen flaky Pixel
CSS-Transitions, Marquee-Ticker und "Loading..."-Spinner zeichnen bei jedem Lauf andere Frames. Visuelle Regressions-Diffs werden vom Rauschen rot.
Lösung: Injiziere ein Stylesheet, das Bewegung direkt nach goto() deaktiviert.
await page.addStyleTag({
content: `
*, *::before, *::after {
animation-duration: 0s !important;
animation-delay: 0s !important;
transition-duration: 0s !important;
transition-delay: 0s !important;
caret-color: transparent !important;
}
`,
});Speicherlecks in lang laufenden Skripten
Offene Seiten halten Render-Trees, JS-Heaps und Netzwerk-Buffer. Eine Schleife, die 10.000 URLs ohne Aufräumen öffnet, lässt deinem Container den Speicher ausgehen.
Lösung: Schließe Seiten explizit. Wiederverwende den Browser, recycle Seiten.
for (const url of urls) {
const page = await browser.newPage();
try {
await page.goto(url);
await page.screenshot({ path: `${slug(url)}.png` });
} finally {
await page.close();
}
}Dateisystem-Schreibvorgänge brauchen Berechtigungen in Docker
Standard-Docker-Images laufen als root, aber viele CI-Setups entziehen diese Rechte. Wenn path: 'out.png' in ein read-only Dateisystem schreibt, schlägt der Aufruf mit EACCES fehl.
Lösung: Schreibe nach /tmp oder ein gemountetes Volume. Oder erfasse in einen Buffer und streame die Bytes upstream.
Puppeteer versus Playwright für Screenshots
Die zwei Bibliotheken haben nahezu identische Screenshot-APIs — page.screenshot(), fullPage, clip, Element-Erfassungen. Die Unterschiede:
- Browser-Unterstützung: Playwright steuert Chrome, Firefox und WebKit. Puppeteer ist Chrome-only.
- PDF-Rendering: Puppeteer hat es nativ. Playwright unterstützt es nur in Chromium-Kontexten.
- Auto-Waiting: Playwright's Locators warten standardmäßig automatisch. Puppeteer braucht explizites
waitForSelector(). - Test-Runner: Playwright bündelt einen. Puppeteer ist nur der Browser-Driver.
Wenn dein einziges Ziel Chrome ist und du bereits einen Test-Runner hast, ist Puppeteer die schlankere Wahl. Für die volle Aufschlüsselung siehe den Puppeteer vs Playwright Deep Dive.
CI/CD-Beispiel: GitHub Actions
Dieser Workflow installiert Node, führt das Screenshot-Skript aus und lädt die Ausgabe als Artefakt hoch. Das --no-sandbox-Flag wird gebraucht, wenn Chrome als root in einem Linux-Container läuft.
name: Capture screenshots
on:
push:
branches: [main]
workflow_dispatch:
jobs:
capture:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Node
uses: actions/setup-node@v4
with:
node-version: '20'
cache: 'npm'
- name: Install
run: npm ci
- name: Run Puppeteer
run: node scripts/screenshot.js
env:
PUPPETEER_ARGS: '--no-sandbox --disable-setuid-sandbox'
- name: Upload artifacts
uses: actions/upload-artifact@v4
with:
name: screenshots
path: out/*.pngIn deinem Skript lies die env-Variable und übergib sie an launch:
const browser = await puppeteer.launch({
args: (process.env.PUPPETEER_ARGS || '').split(' ').filter(Boolean),
});Für Docker nutze das offizielle puppeteer/puppeteer-Image. Es liefert die System-Bibliotheken mit, die Chrome braucht, wie Roboto, libxss und Schriften.
Wenn du Screenshots in eine Regressions-Suite verdrahtest, deckt unser Leitfaden zu visuellen Regressionstests Diff-Schwellen, Baseline-Verwaltung und Flake-Budgets im Detail ab. Für gehostete Alternativen siehe die Übersicht der besten Screenshot-APIs.
Wo ScreenSnap Pro hineinpasst
Wenn du auch schnelle Desktop-Screenshots brauchst — Bug-Reports, Design-Feedback, Terminal-Captures — ohne Code zu schreiben, ist ScreenSnap Pro eine einmalige Desktop-App für 29 $ für Mac und Windows. Es hat Annotation, Blur und sofortiges Cloud-Sharing. Es ersetzt Puppeteer nicht für Automatisierung, deckt aber die manuelle Seite eines Entwickler-Screenshot-Workflows ab.
Häufig gestellte Fragen
Was ist der Unterschied zwischen page.screenshot() und elementHandle.screenshot()?
page.screenshot() erfasst den Viewport oder die volle Seite mit fullPage: true. elementHandle.screenshot() erfasst nur die Bounding Box eines DOM-Elements und scrollt es zuerst in den Sichtbereich. Nutze die page-Methode für volle Erfassungen. Nutze die element-Methode für Diagramm-Exporte, OG-Cards oder Komponenten-Snapshots.
Wie erstelle ich einen Full-Page-Screenshot in Puppeteer?
Übergib fullPage: true an page.screenshot(). Puppeteer vergrößert den Viewport auf die Dokumenthöhe, malt alles und erfasst dann. Wenn deine Seite Bilder lazy lädt, scrolle die Seite zuerst oder rufe await page.waitForNetworkIdle() auf, um sicherzustellen, dass alle Assets vor dem Snap geladen sind.
Kann ich PDFs mit Puppeteer generieren?
Ja. Rufe await page.pdf({ path: 'out.pdf', format: 'A4' }) auf. Es funktioniert nur im headless-Modus. Du kannst Ränder, Seitengröße, Header, Footer, Querformat und printBackground: true setzen, um CSS-Hintergrundfarben zu behalten. Druck-Stylesheets (@media print) werden respektiert, sodass du Nav und Banner sauber ausblenden kannst.
Funktioniert Puppeteer in CI?
Ja. Du brauchst zwei Dinge: Starte Chrome mit --no-sandbox, wenn er als root in Linux-Containern läuft, und installiere die System-Schriften und -Bibliotheken, die Chrome braucht. Das offizielle puppeteer/puppeteer-Docker-Image bündelt beides. GitHub Actions, GitLab CI, CircleCI und Vercel unterstützen es alle out of the box.
Puppeteer oder Playwright für Screenshots?
Wähle Puppeteer, wenn du nur Chrome im Visier hast und eine kleinere, schnellere Installation plus native PDF-Unterstützung willst. Wähle Playwright, wenn du Cross-Browser-Abdeckung (Firefox, WebKit), Auto-Waiting-Locators oder einen eingebauten Test-Runner brauchst. Die Screenshot-APIs sind nahezu gleich, sodass eine Portierung in beide Richtungen meist Suchen-und-Ersetzen ist.
Wie mache ich einen Screenshot einer eingeloggten Seite?
Zwei Optionen: Steuere das Login-Formular einmal mit page.type() und page.click() und erfasse dann. Oder setze Cookies direkt mit page.setCookie() und überspringe das Formular. Der Cookie-Ansatz ist schneller und zuverlässiger in CI. Speichere Cookies einmal in einer JSON-Datei und nutze die Datei dann über Läufe hinweg wieder.
Warum ist mein Puppeteer-Screenshot leer oder unvollständig?
Drei übliche Verdächtige. Eins: Die Seite lädt lazy und dein Snap feuert, bevor Bilder rendern. Behebe es mit waitForNetworkIdle(). Zwei: Animationen sind mitten im Frame. Deaktiviere sie mit einer CSS-Injektion. Drei: Das Element, das du targetierst, ist display: none oder hat null Höhe. Prüfe zuerst mit page.evaluate(() => document.querySelector('#x').getBoundingClientRect()).
Morgan
Indie DeveloperIndie developer, founder of ScreenSnap Pro. A decade of shipping consumer Mac apps and developer tools. Read full bio
@m_0_r_g_a_n_